
こんにちは。光学、光でのお困りごとがありましたか?
光ラーニングは、「光学」をテーマに様々な情報を発信する光源を目指しています。情報源はインターネットの公開情報と、筆者の多少の知識と経験です。このページでは、Zemaxコミュニティで注目されているトピックから、GPU計算とマルチコア計算について取り上げます。
Zemaxコミュニティについては、こちらのページ で概略を説明しています。
結論
- OpticStudioの光線追跡はCPUのみで実行され、少なくとも2022/4/15時点で、GPUは使用されません。
- マルチCPUによる時間短縮はアムダールの法則で律速され、思っているよりも早く飽和します。ざっくり、8コアか12コアあたりがコスパとして良い選択かもしれません。
このページの使い方
このページでは、Zemaxコミュニティに投稿されたトピック中から、よく参照されているもの、コメントが多いもの、筆者が気になったものを取り上げて紹介します。よくある疑問や注目されているトピックについての情報を発信することで、何かしらの気づきとなれば幸いです。
興味を持ったトピックに質問やコメントをしてみると、世界のOpticStudioユーザやZemaxエンジニアからの回答があるかもしれません。
OpticStudioの計算速度の改善
シミュレーションソフトの計算を待っている時間は短いに越したことはありません。1回の計算サイクルが短ければ、開発にかかる期間は短くなりますし、改善ステップを多く試すことでよりよい設計に到達できる可能性が高まります。このページでは、コミュニティでよく参照されているトピックから、「GPU」と「マルチコアCPU」に関する議論があったので紹介します。
GPUを使用した光線追跡
トピックへのリンク: https://community.zemax.com/got-a-question-7/ray-tracing-with-gpu-217
質問は、「NVIDIA GPUを用いて光線追跡計算を高速化できますか?」でした。
ディスカッションの内容
ZemaxのエンジニアAllieさんの回答によれば、結論として「OpticStudioはGPUでの光線追跡に対応していない。」です。これは、OpticStudio自体の機能として対応していない、という意味で、GPUリソースとの橋渡しのツールを活用することで実現は可能のようです。Allieさんが紹介しているウェビナーではCUDA Toolkit (?) を介して光線追跡計算を高速化させた事例が紹介されています。
その後、別のユーザから「将来的に、OpticStudio自体の機能としてGPUでの光線追跡に対応する計画はあるか?」という質問がありますが、これへの回答はありませんでした (2021/9/2 執筆時)。これまでのリリース情報によれば、GPU対応の具体的な計画は見つかりませんでした。
いまのところ、商用の光線追跡ソフトウェアでGPUに対応しているのは、FREDmpcのみです。FREDは米国 Photon Engineering LCC (https://photonengr.com/) が開発する光線追跡ソフトウェアで、特にオプトメカ設計に強みがあります。迷光解析など膨大な光線追跡を要する解析において、GPUの恩恵は大きくなります。日本の代理店は CBS Japan (https://cbsjapan.com/) です。
マルチコアCPUを使用したノンシーケンシャル光線追跡
質問にはテスト結果も含まれており参考になります。内容は、「4コアのノートPCと32コアのワークステーションでノンシーケンシャル光線追跡を行っている。単純な光線追跡はおよそ8倍になった。しかし最適化では、むしろワークステーションの方が低速な結果となった。なぜか?」でした。
ディスカッションの内容
ユーザのテストでは、4コアのノードPCで5~8分で終わる最適化が、32コアのワークステーションでは15分ほどかかっていました。タスクマネージャでCPUの稼働状況を確認したところ、最適化中のワークステーションのCPUの稼働率は低いことが分かりました。一方で、最適化を伴わない単純なノンシーケンシャル光線追跡は、ワークステーションのCPU稼働率は高い(~87%)結果となりました。
これに対するZemaxのエンジニアSandrineさんからの回答は、「最適化時の解析光線本数があまり多くない場合、多すぎるコア数は逆にペナルティになる。」でした。例として、Intel-Xeon-Platinum-8180 28 コア (56 スレッド) で、解析光線本数とコア数を変えたときの、(おそらく)最適化完了までにかかる時間の実測結果は興味深いです。

例えば、解析光線本数217 = およそ13万本を見ます。コア数1~8コアまでは計算時間が下がっていきますが、16コア以上にすると逆に長い時間がかかってしまって、最終的に1コアと56コア (スレッド) は同じくらい、という結果になります。これが、解析光線本数が少ない場合、マルチコアのメリットがなくなってペナルティとなる、という意味です。
これに対して、単純なノンシーケンシャル光線追跡の実行だと、上でみられたようなペナルティは確認できなかったと、Sandrineさんは述べています。表の中の数字はとても小さいので、この結果がどのくらい有用であるかは不明ですが、少なくともZemaxとしても最適化中にはマルチコアCPUの効果は薄まることは認識されているようです。
アムダールの法則 (Amdahl’s law) が律速している?
「最適化においてはマルチコアCPUの効果が薄くなる」について、要因の1つとして示されているのが、アムダールの法則です。Wikipediaによれば、「その計算機の並列度を上げた場合に、並列化できない部分の存在、特にその割合が「ボトルネック」となることを示した法則である。」とのことです[1]。
OpticStudioの最適化に関して言えば、ボトルネックとなるのは、評価関数 (Merit Function) の計算です。また、タスクを分散するのにも時間(オーバーヘッド)がかかるかもしれません。最適化の1回の計算を想像すると以下の流れになります。
- 解析光線本数をコア数で割って(タスク分割)
- 各コアで計算して(ここは並列計算)
- その計算結果を1つにまとめて(計算結果の集計中)
- 評価関数の各オペランドの結果を更新して評価関数地を算出(シングルスレッド)
アムダールの法則によれば、2と4の作業にかかる時間の比率によってマルチコアの効果は頭打ちになります。さらに、タスクの分散と集計にかかる時間(1+3)がコア数に応じて増大するならば、コア数を増やすこと(2)による時間短縮の効果を相殺してしまったり、逆に時間をかけてしまうこともあり得そうです。
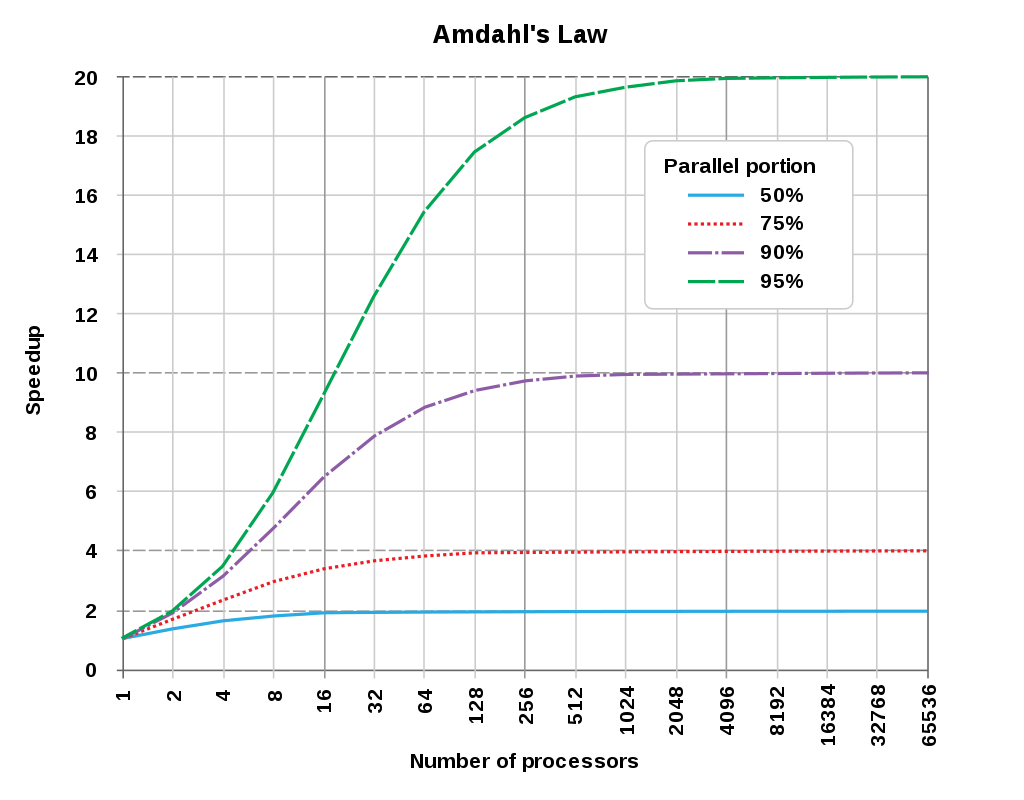
アムダールの法則の法則を教えてくれたITエンジニアさんのコメントは、「OpticStudioの並列計算の割合は50~75%くらいだと思うので、コア数は8~12が適切なのでは?」でした。この割合は、ノンシーケンシャルモードの場合でしょうか。検討している光学系のデータによって異なってくるものと思います。少なくとも、ノンシーケンシャルモードの最適化において、力こそパワーでコア数を増やす物量作戦は効果が薄いことは確かです。
ノンシーケンシャル光線追跡で使用するコア数を指定
ノンシーケンシャルモードで光線追跡を実行する場合、使用するコア数を指定できます。光線追跡コントローラに、コア数のオプションがあります。他のオプションについては、ノンシーケンシャルの3つの特技_OpticStudioのノンシーケンシャルモードについて (4 fin) もご参照ください。
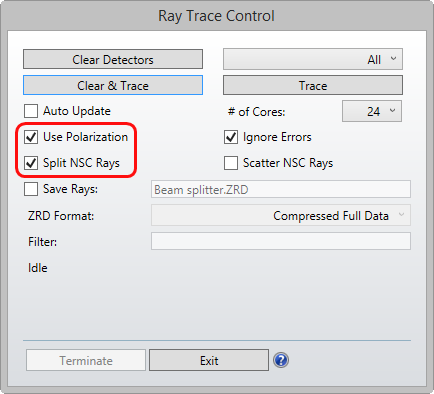
だた、困ったことに、最適化を実行するときにはコア数を明示的に設定できません。少し裏技のようですが、ZPLマクロを使うことでマルチスレッド時のコア数を指定することができます。この情報は、コミュニティのこちらのスレッド から発見できます。具体的には、SYSP 901, n (nが使用したいコア数) です。通常の光線追跡を行う場合はコア数の恩恵を受けるために多いコア数を、最適化を行う場合はペナルティを考慮した最適なコア数をそれぞれ指定できそうです。本格的に最適化を行う前に、以下のようなプロセスで最適化の条件を探索するのがよいでしょう。
- 最適化に必要な解析光線本数を決める。
- 簡単な条件で最適化の実験を行い、最短となるコア数を見つける。
- いろいろな条件やターゲットで最適化を行う。
前提として、コア数が計算時間短縮に直結しない、という認識は重要になります。高額なワークステーションを導入しても、128コアで1/100の計算時間!とは残念ながら、なりません。最適化がより短い時間で完了するような、他のアプローチ (ノウハウ) を検討するのも手かもしれません。
まとめ
このページでは、Zemaxコミュニティに投稿された「GPU」と「マルチコアCPU」による光線追跡の高速化をトピックに取り上げ、説明を加えました。OpticStudioのGPU対応は可能性が薄そう、マルチコアCPUは思っているよりも早く効果が頭打ちになる、という少し残念な結論となりました。ただ、これらを認識することは大事なステップになると思います。 他にも計算時間短縮に貢献できそうな情報があれば、光ラーニングでも取り上げたいと思います。
<参考>
[1] Wikipedia, アムダールの法則


コメント