
こんにちは。光学、光でのお困りごとがありましたか?
光ラーニングは、「光学」をテーマに様々な情報を発信する光源を目指しています。情報源はインターネットの公開情報と、筆者の多少の知識と経験です。このページでは、Zemaxコミュニティで注目されていて、光ラーニングでも過去に取り上げた、ノンシーケンシャルモードとマルチコアCPUに関するトピックが更新されていたので、追加された情報について説明します。
Zemaxコミュニティについては、こちらのページ で概略を説明しています。
結論
- ノンシーケンシャルモードの最適化では、アムダールの法則により、コア数は8~12程度が最適な妥協点になりそうです。ただ、光学系や処理内容に依存するので、事前の検証が必要です。
- 光学系が複雑で、かつ解析光線本数が少ない時は、特にマルチCPUの恩恵や小さく、むしろ計算時間はかかる傾向にあるので、コア数を減らす検証をしてみると良いです。
このページの使い方
このページでは、Zemaxコミュニティに投稿されたトピック中から、よく参照されているもの、コメントが多いもの、筆者が気になったものを取り上げて紹介します。よくある疑問や注目されているトピックについての情報を発信することで、何かしらの気づきとなれば幸いです。
ノンシーケンシャル光線追跡でワークステーションがノートPCより遅い
トピックへのリンク:
ノンシーケンシャルシミュレーションの問題、ワークステーションがノートPCより遅い
このトピックは以前、光ラーニングでも取り上げました。GPUとマルチコアCPU_Zemaxコミュニティ注目トピック (2) を参照してください。
他にも、ノンシーケンシャル光線追跡が低速で困っている場合、確認してみるポイントを以下のページで取り上げているので、こちらもご参照ください。
- NSCが遅い時の対応(1) – 光線分割_Zemaxコミュニティ注目トピック (12)
- NSCが遅い時の対応(2) – 光線散乱_Zemaxコミュニティ注目トピック (13)
- NSCが遅い時の対応(3) – CAD_Zemaxコミュニティ注目トピック (14)
前回までの結論
マルチコアCPUの数を増やしても、ノンシーケンシャルモードでの”最適化”が高速化できない、それどころかノートPCの方がワークステーションよりも速い現象について、前回取り上げたときのトピックの結論は以下の通りでした。
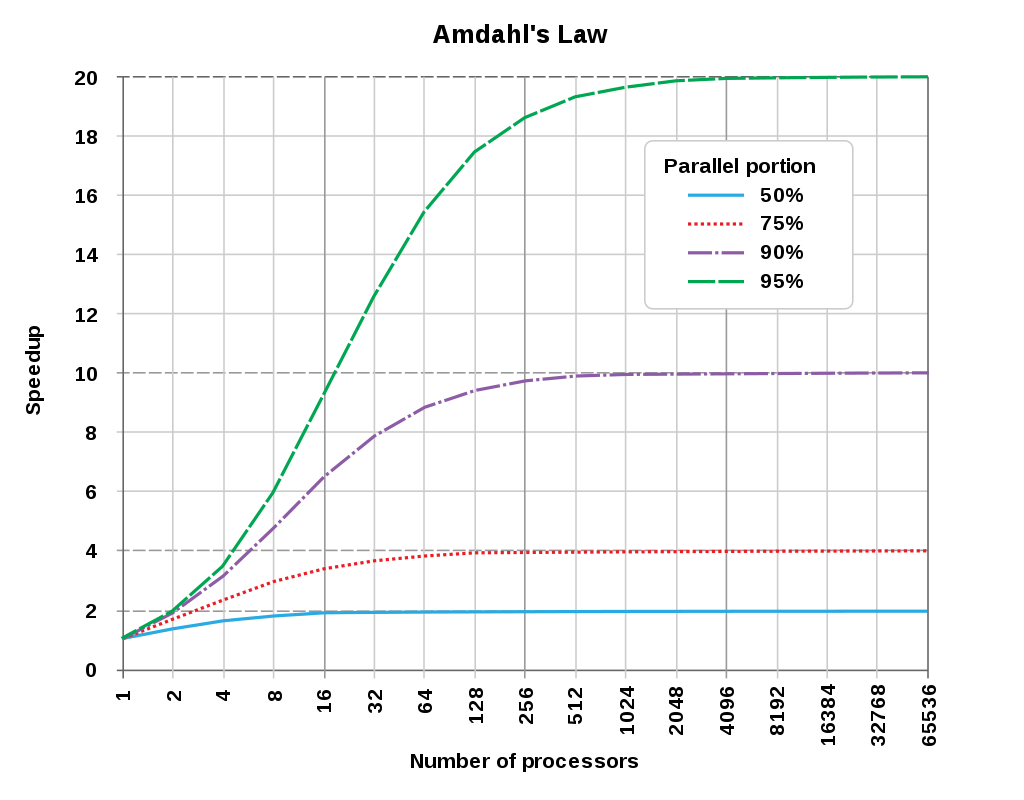
アムダールの法則に従って、メリットファンクション(評価関数)の計算がボトルネックとなってマルチコアCPUによる高速計算の恩恵は小さくなります。Zemaxのエンジニアさんのコメントでは、最適なコア数は8~12ではないか、との見解も示されました。
もともとマルチCPUの数と最適化の速度について調査していたユーザから、追加のサマリーが共有されていました。よい指針となりそうなので、翻訳してお伝えします。
- PCのプロセッサを調整しても光線追跡の速度には影響しません。
- 多すぎるコア数は計算時間に悪影響をお呼びします。8コアはよい妥協点です。
- 最適なコア数を見出すのは、事前のテストが有効です。マクロでルーティンを回します。
- ただし、光線追跡の最適コア数が、最適化の最適コア数とは限りません。最適化に適したコア数の決定にも、事前のテストが必要です。おそらく、8~12コアが良い妥協点です。
- グローバル最適化であれば、コア数が多い方が良いです。
クロックの速いCPU + 20コアもよい選択肢?
あるユーザは2017年に、Intel i9-7900x (ターボモードで最大4.5GHz)を選択し、物理コア数10、スレッド数20は使用率100%で高速だった、とコメントしています。
残念ながら、「どのようなモデルで、何をしていたか」が分からないので、たまたまこのユーザの目的に対してはその組み合わせが最適だっただけ、とも言えます。
アムダールの法則以外のマルチコアCPUの利得の律速
Markさんから、OpticStudioの処理においてマルチコアCPUの効果を抑制しうるポイントが示されていました。光ラーニングでも取り扱ったポイントもあるようなので、そちらも参照してください。
- 新しいスレッドを作成するとき、システム全体をコピーする必要があります。光学系の分散と結果の集約によって、並列化できない領域が増えます。これについては、NSCが遅い時の対応(3) – CAD_Zemaxコミュニティ注目トピック (14) でも触れた内容になります。
- ノンシーケンシャル光線追跡では、追跡する光線数が決まっていないので、計算時間の見積もりが難しいです。これは、光線の分割や散乱によって、セグメント数が雪崩式に大きくなることに起因しています。これについえは、NSCが遅い時の対応の(1)と(2)で触れています。
- ハイパースレッディング (物理コアは32なのに、64コアあるようにする機能)はオフにしてみては?Markさんのコメントからは、「ハイパースレッディングによるコア増加は、計算速度の改善に寄与しない」というニュアンスが感じられます。検証結果がないか、調査してみたいと思います。
Zemax開発メンバーからのコメント
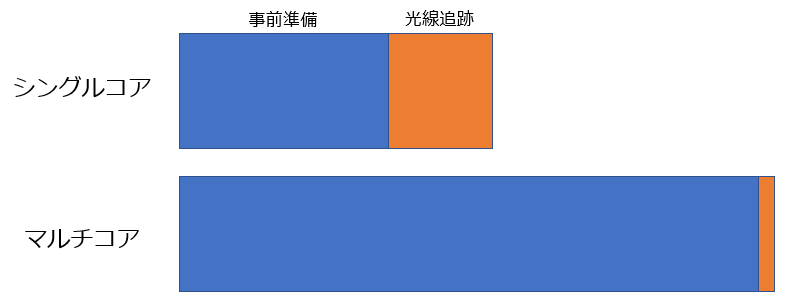
Sandrineさんから、Zemax開発チームメンバのコメントが共有されました。これまでの議論を肯定するものでした。コア数を増やしすぎると、光線追跡ではなくメモリへのアクセスに時間がかかり、結果として計算時間全体が長くなります。この傾向は、光学系が複雑で、かつ光線追跡本数が少ない時に顕著になります。ちょうど、下図のようなイメージになるかと思います。
まとめ
光ラーニングでも以前取り上げたトピックが更新されていたので、再度取り上げました。このページでは、Zemaxコミュニティに投稿された「ノンシーケンシャルモードの最適化で、ワークステーションがノートPCより遅い問題」について説明しました。
マルチCPUと光線追跡の高速化の関係について興味深いディスカッションが行われていました。アムダールの法則は、並列計算の重要な特性として理解しておくと良さそうです。結論としては、「最適なマシンスペックは、各ユーザが使用したいファイルとの相性で決まる」ということなので、大規模計算に入る前に、いかに事前検証を実施するかにかかっています。


コメント